
Previously… #
In the first article we introduced the concept of the Persistence Context and explored some of its quirks using an example.
We focused on how it can help us (or not so much) when fetching entities, but how does it actually read and load those entities? And why exactly the repeatable-reads feature exists given the limitations that we saw in the last article?
Let’s check it out!
Hibernate’s entity load process #
When we request that Hibernate load an entity it checks, in order, the first-level cache, the second-level cache (if enabled), and the datasource.
Assuming that we are requesting a given entity for the first time we would have a miss on both caches, loading the data directly from the database.
When the data is returned, it comes with two objects: the actual entity and the entity loaded state. The loaded state is the converted JDBC ResultSet to an Object[] and is used to determine which changes were made to the entity before flushing it back to the database. Both the entity and the loaded state are stored in the first-level cache.

Suppose now that we request the same entity using the EntityManager.find method. This will go to the Persistence Context and trigger a cache hit, returning the entity without going to the database

If we request the same entity using a JPQL/HQL query, we will have the same load steps, but in this case there is no way for the EntityManager to know that our query gets an entity that is already loaded.
Because of that it will request for the object to be loaded even if the result is not persisted in the first-level cache, given that the entity is already there.

The second-level cache stores entities loaded states directly, so if it’s enabled we can avoid going to the DB when re-requesting the entity. If not enabled, we undergo the same process as the first time we requested the entity.
Entity states in the Persistence Context #
Inside the Persistence Context we can have an entity in four different states: New Transient, Managed, Removed, or Detached. Each one happens at different stages of the entity lifecycle:
- New Transient: an entity that the Persistence Context is still not aware it exists, for example a newly created entity that will be inserted into the database;
- Managed: when an entity is persisted it goes to the Managed state. At this stage the Persistence Context becomes aware of changes made to the entity using the loaded state explored on the prior section. This is used to determine when and how an entity should be flushed to the DB;
- Removed: when we use
removeon a managed entity we change it to the removed state. Entities in this state are also flushed; - Detached: when we
detachorclearthe context entities go to the detached state. These entities are not managed by the persistence context anymore unless they are persisted again;
The diagram below represents the relation between each state (found on this great article by Vlad):
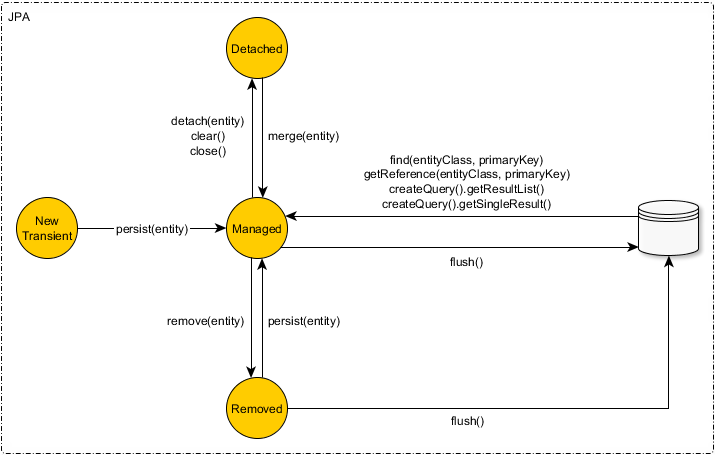
When we attempt to load an entity from the first-level cache what the EntityManager actually looks for are the Managed entities in the Persistence Context. If the entity is not found we load it from the datasource to the first-level cache, setting it as a Managed entity.
Hibernate’s repeatable reads #
Everything explored above allows Hibernate to have application-level repeatable reads: querying for an entity will always return the same result if said entity is already loaded in the Persistence Context, given that no changes were made in the same transaction.
This feature is essential for Hibernate’s persistence design, preventing lost updates in concurrent scenarios.
With that in mind, repeatable reads can lead to inconsistent results when dealing with long-running transactions.
As we saw above, if we make a JPQL/HQL query for a entity that was already loaded in the Persistence Context the cache will be ignored and the entity will be loaded directly from the database. Given that, because of the repeatable-reads feature, the newly loaded entity is ignored and the previously loaded data remains unchanged in the Persistence Context, even if that database snapshot differs from the current loaded state.
This is by design, since Hibernate is more focused on consistent writes than reads. The diagram below illustrates a long-running transaction where the entity data is changed during the operation (source).

In this case we don’t want changes made to the entity during the transaction to get lost because of changes made in another operation.
If read-only views with updated, fresh data is the objective it’s way more recommended to use SQL projections, since they bypass the first-level cache going directly to the datasource.
Conclusion #
Hibernate and JPA are very robust frameworks that facilitate working with databases in Java environments where we have complex relations and operations between entities. Because of that, some of the inner workings of those tools are complex and some of the errors that can come with them are not the clearest.
With both this article and the first one, I hope that the specifics of entity loading is clearer and that it helps you to design better code using those frameworks. Happy coding :)!