
Anteriormente… #
No primeiro artigo introduzimos o conceito do Persistence Context e exploramos algumas de suas peculiaridades usando um exemplo.
Focamos em como ele pode nos ajudar (ou não tanto) ao buscar entidades, mas como ele realmente carrega e gerencia essas entidades? E por que o recurso de leituras repetíveis (repeatable-reads) existe, dadas as limitações que vimos no último artigo?
Vamos dar uma olhada!
O processo de carregamento de entidades do Hibernate #
Quando utilizamos o Hibernate para carregar uma entidade, ele verifica, em ordem, o cache de primeiro nível, o cache de segundo nível (se habilitado) e o banco de dados.
Assumindo que estamos solicitando uma entidade pela primeira vez, teríamos um miss em ambos os caches, carregando os dados diretamente do banco de dados.
Quando os dados são retornados, eles vêm com dois objetos: a entidade e o estado da entidade (entity loaded state). O estado é o ResultSet JDBC convertido para um Object[] e é usado para determinar quais mudanças foram feitas na entidade antes de enviá-la de volta ao banco de dados (flushing). Tanto a entidade quanto o estado da entidade são armazenados no cache de primeiro nível.

Suponha agora que solicitamos a mesma entidade usando o método EntityManager.find. Como os dados já estarão no Persistence Context teremos um cache hit, retornando a entidade sem ir ao banco de dados.

Se solicitarmos a mesma entidade usando uma consulta JPQL/HQL, teremos os mesmos passos de carregamento, mas neste caso não há como o EntityManager saber que nossa consulta requisita uma entidade que já está carregada.
Por causa disso, ele solicitará que o objeto seja carregado mesmo que o resultado não seja persistido no cache de primeiro nível, já que a entidade já está lá.

O cache de segundo nível armazena diretamente os estados das entidades então, se estiver habilitado, podemos evitar ir ao DB ao solicitar a entidade novamente. Se não estiver habilitado, passamos pelo mesmo processo da primeira vez que solicitamos a entidade.
Estados da entidade no Persistence Context #
Dentro do Persistence Context, podemos ter uma entidade em quatro estados diferentes: New Transient, Managed, Removed ou Detached. Cada um ocorre em diferentes estágios do ciclo de vida da entidade:
- New Transient: uma entidade que o Persistence Context ainda não sabe que existe, por exemplo, uma entidade recém-criada que será inserida no banco de dados;
- Managed: quando uma entidade é persistida, ela passa para o estado Gerenciado. Neste estágio, o Persistence Context fica ciente das mudanças feitas na entidade usando o estado da mesma, explorado na seção anterior. Isso é usado para determinar quando e como uma entidade deve ser enviada para o DB;
- Removed: quando usamos
removeem uma entidade gerenciada, a mudamos para o estado removido. Entidades neste estado também são enviadas para o banco de dados; - Detached: quando
detachamos ouclearamos o contexto, as entidades vão para o estado desanexado. Essas entidades não são mais gerenciadas pelo persistence context, a menos que sejam persistidas novamente;
O diagrama abaixo representa a relação entre cada estado (encontrado neste ótimo artigo do Vlad):
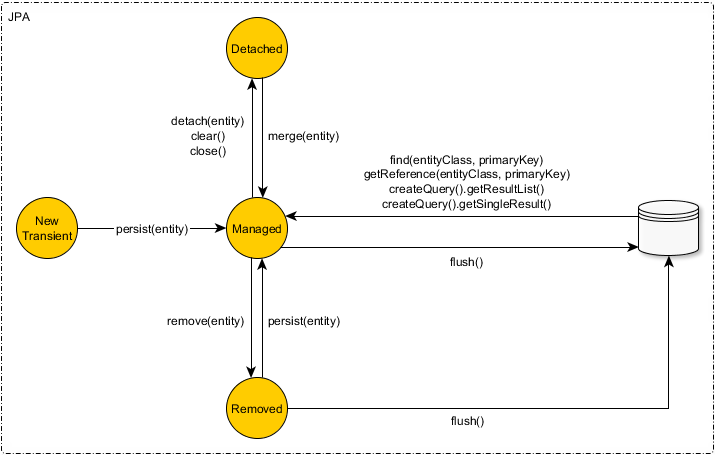
Quando tentamos carregar uma entidade do cache de primeiro nível, o que o EntityManager procura são as entidades Gerenciadas (Managed) no Persistence Context. Se não for encontrada, a carregamos da fonte de dados para o cache de primeiro nível como uma nova entidade gerenciada.
Leituras repetíveis do Hibernate (Hibernate’s repeatable reads) #
Tudo o que foi explorado acima permite que o Hibernate implemente leituras repetíveis a nível de aplicação: consultar uma entidade sempre retornará o mesmo resultado se essa entidade já estiver carregada no Persistence Context, desde que nenhuma mudança tenha sido feita na mesma transação.
Este recurso é essencial para o design de persistência do Hibernate, evitando que atualizações de entidades sejam perdidas em cenários concorrentes.
Com isso em mente, leituras repetíveis podem levar a resultados inconsistentes ao lidar com transações de longa duração.
Como vimos acima, se fizermos uma consulta JPQL/HQL para uma entidade que já estava carregada no Persistence Context, o cache será ignorado e a entidade será carregada diretamente do banco de dados. No entanto, devido ao recurso de leituras repetíveis, a entidade recém-carregada é ignorada e os dados carregados anteriormente permanecem inalterados no Persistence Context, mesmo que o snapshot do banco de dados seja diferente do estado carregado atual.
Isso é por design, já que o Hibernate está mais focado em escritas consistentes do que em leituras. O diagrama abaixo ilustra uma transação de longa duração onde os dados da entidade são alterados durante a operação (fonte).

Neste caso, não queremos que as mudanças feitas na entidade durante a transação sejam perdidas por causa de mudanças feitas em outra operação.
Se o objetivo for apenas a leitura de dados atualizados em relação a fonte de dados é muito mais recomendado usar projeções SQL, pois elas ignoram o cache de primeiro nível, indo diretamente para o BD.
Conclusão #
Hibernate e JPA são frameworks muito robustos que facilitam o trabalho com bancos de dados em ambientes Java onde temos relações e operações complexas entre entidades. Por causa disso, alguns dos mecanismos internos dessas ferramentas são complexos e alguns dos erros que podem surgir com elas não são os mais claros.
Com este artigo e o anterior, espero que alguns dos detalhes relacionados ao carregamento de entidades estejam mais claros e que isso ajude você a projetar um código melhor usando esses frameworks. Boa programação :)!